本文主要讲述shatter的含义,发生的条件,形式,应用
##
##
csv文件,json格式文件导入
1 | # Filename: quotes_fromcsv.py |
web API获取数据
获取的已经是数据部分 而不是HTML文件,不需要再进行解析
1 | >>> r = requests.get('https://api.douban.com/v2/book/1084336') |
NLTK语料库
1 | import requests |
1 | 转换成常规时间 |
选择方式
1 | 索引 |
1 | djidf.loc[1:5, ['code','lasttrade']] |
1 | quotesdf[(quotesdf.index >= '2017-01-01') & (quotesdf.index <= '2017- 03-31') & (quotesdf.close >= 80)] |
排序
1 | tempdf = djidf.sort_values(by = 'lasttrade', ascending = False) |
计数统计
1 | tempdf['month'].value_counts() |
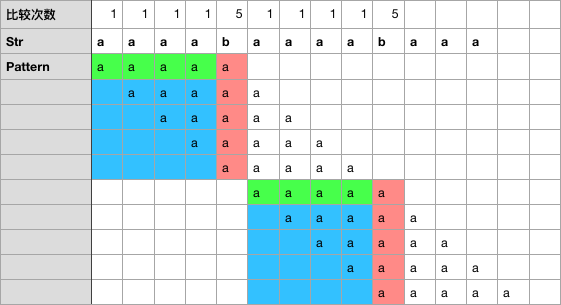
比较次数: 红色 + 蓝色
蓝色部分是相比暴力求解,节省下的比较次数
从比较次数可以看出,呈现 1 1 1 1 5 这样的周期
一般化结论:
- 一个周期内的比较次数:1 * (M - 1) + M
- 周期长度:M
- 周期个数:N/M
- 比较总次数: 周期个数 * 一个周期内额比较次数 = (2 - 1/M)*N < 2N
因此是线性
接下来证明,上述情况是KMP算法的最差情况
- 模式串
当模式串长度为M,首字符和其他字符全都相等(假定都为a),模式串存在最长的k前缀和k后缀, next数组呈现递增样式:-1,0,1,2…- 需要匹配的字符串
- 串成周期性分布,周期为M
- 前M-1都为a,第M位不等于a
模式串的最坏情况比较好理解,因为每次当s[i] 不等于 P[j]时,j = next[j],一直按照next数组值进行回溯,当模式串全相等时,next数组呈现递增,每次回溯一个位子,因此比较次数是最多的
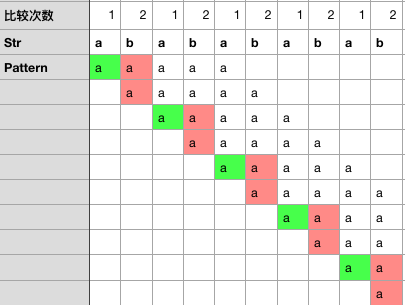
比较总次数:15 < 18
- 模式串
当模式串的首字符和其他字符都不相等时,模式串不存在相等的k前缀和k后缀,next数组全为-1- 需要匹配的字符串
无要求
因为Python可能会缓存写入的数据 如果程序异常崩溃了 数据就不能写入到文件中 所以为了安全起见 文件用完以后要养成 主动关闭文件的习
格式
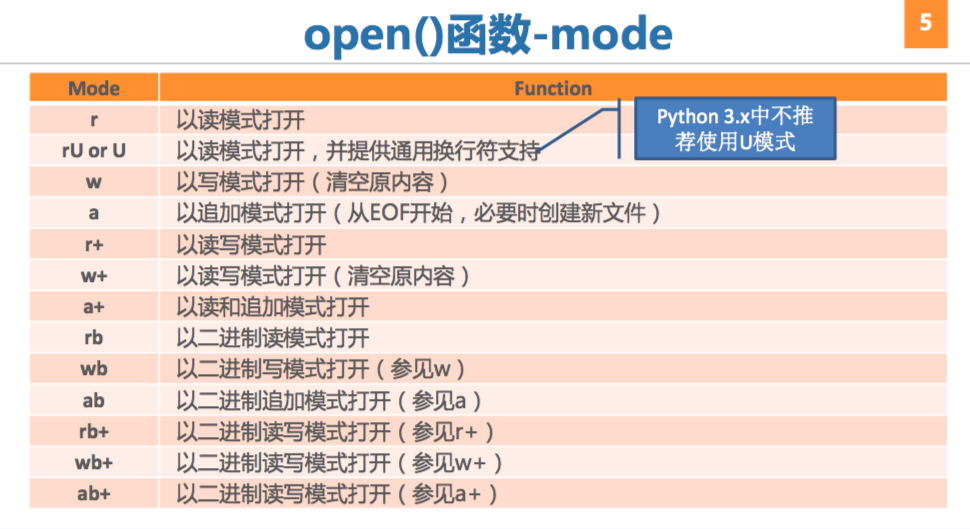
1 | file_obj = open(filename, mode='r', buffering=-1) |
mode为可选参数,默认值为r
f.write(str)
1 | >>> f = open('firstpro.txt', 'w') |
f.read()
f.readlines()
1 | f = open(r'companies.txt') |
f.seek(offset , whence=0)
− 在文件中移动文件指针,从 whence(0表示文件头部,1表示 当前位置,2表示文件尾部)偏 移offset个字节
– whence参数可选,默认值为0
Requests官网:http://www.python-requests.org/
1 | >> import requests |
re.json()
re.content()
自动推测文本编码,并进行解码
修改编码
1 | from bs4 import BeautifulSoup |
操作
标准类型运算符
1 | 值比较: < > <= >= == != |
序列类型运算符
获取,重复,连接,判断
1 | 序列类型转换内建函数: list() str() tuple() |
1 | >>> [x for x in range(10)] |