模型定义
特征 x:m*n
label y:m*1
不同的x,@对应一个不同的二项分布
这些二项分布可以通过统计求得
改进
不按照x是否相同,来统计其二项分布的分布律,而每一个样本点都看做一个独立二项分布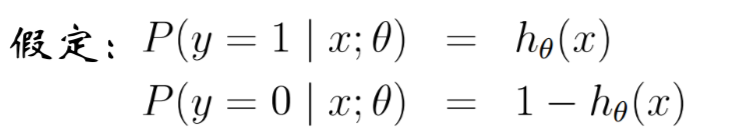
这样的特点就是这样的二项分布只有俩种,分别为
并且能合并表示为

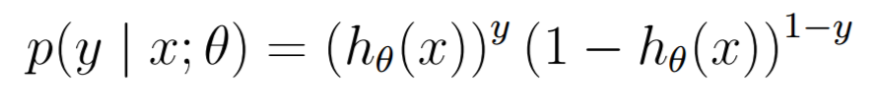
目标函数——交叉熵
小目标:对于每一个样本点,分别求出一个分布,使得俩者分布差距最小
模型目标:所有的样本差距之和最小
KL散度
Kullback-Leibler Divergence,即K-L散度,是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息。
参考链接:https://www.jianshu.com/p/43318a3dc715
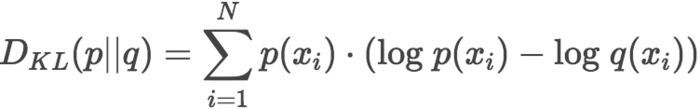
K-L散度是数据的原始分布p和近似分布q之间的对数差值的期望
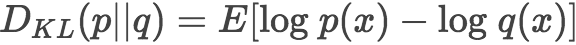
其中分布p是我们上面统计出来的数据分布
KL散度与交叉熵的关系

目标表示
小目标:对于每一个样本点,分别求出一个分布,使得俩者分布差距最小
模型目标:所有的样本差距之和最小
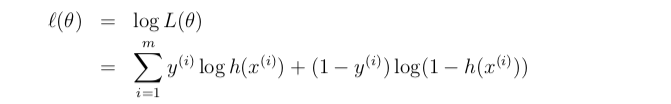
目标函数——极大似然估计
同样认为对于每一个样本点都是一个P(y)的二项分布
L() 代表获得到样本的概率,希望概率越大越好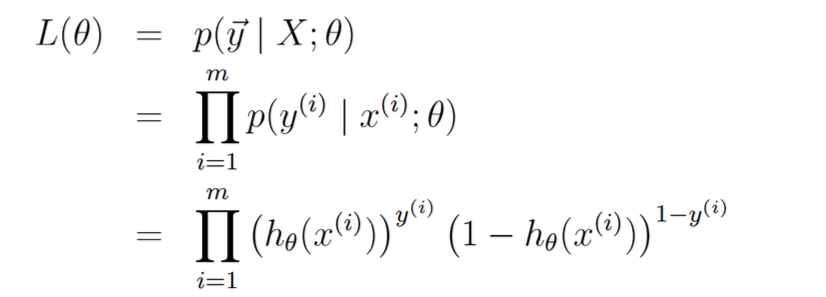
求对数似然
模型求解


参考:
- KL散度的介绍:https://www.jianshu.com/p/43318a3dc715
- KL散度,交叉熵的关系;在Logistic回归中的应用
- 邹博老师的课件