本地数据获取
文文件的打开,读写和关闭件
- 打开后才能进行读写
- 为什么需要关闭?
因为Python可能会缓存写入的数据 如果程序异常崩溃了 数据就不能写入到文件中 所以为了安全起见 文件用完以后要养成 主动关闭文件的习
文件的打开
格式
1
file_obj = open(filename, mode='r', buffering=-1)
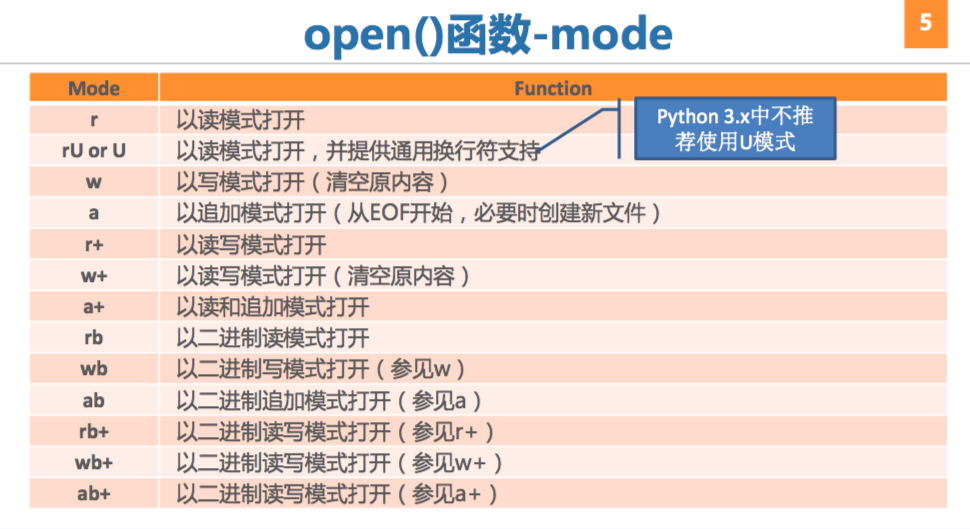
mode为可选参数,默认值为r
- buffering也为可选参数,默认值为-1(0代表不缓冲,1或大于1的值表示缓冲一行或指定缓冲区大小)
- 在Python中 二进制文件可以不使用缓冲
- 文本文件必须要使用缓冲
- open()函数-mode
- 返回值
- open()函数返回一个文件(file)对象
- 文件对象可迭代
文件相关函数
f.write(str)
1
2
3
4
5
6>>> f = open('firstpro.txt', 'w')
>>> f.write('Hello, World!')
>>> f.close()
with open(‘firstpro.txt’, ‘w’) as f:
f.write() #能进行文件异常处理,更加简洁有效f.read()
- file_obj.read(size)
- 从文件中至多读出size字节数据,返回一个字符串
- file_obj.read()
- 读文件直到文件结束,返回一个字符串
- 注意文件指针的概念,可以用f.tell() 查看
- file_obj.read(size)
f.readlines()
- readlines返回一个列表 Python中不删除换行符,需要程序员自己完成
1
2
3
4
5
6
7f = open(r'companies.txt')
cNames = f.readlines()
print cNames
f.close()
Output:
['GOOGLE Inc.\n', 'Microsoft Corporation\n', 'Apple Inc.\n', 'Facebook, Inc.']
- readlines返回一个列表 Python中不删除换行符,需要程序员自己完成
f.seek(offset , whence=0)
− 在文件中移动文件指针,从 whence(0表示文件头部,1表示 当前位置,2表示文件尾部)偏 移offset个字节
– whence参数可选,默认值为0
网络数据获取
获取过程
- 抓取
- urllib内建模块
- urllib.request : 已经逐渐被Request第三方库替代
- Requests第三方库:适合中小型网络爬虫的开发
- Scrapy框架:大型
- urllib内建模块
- 解析
- BeautifulSoup库 : https://www.crummy.com/softwa re/BeautifulSoup/bs4/doc/
- re模块 : https://docs.python.org/3.5/libr ary/re.html
Requests库
Requests官网:http://www.python-requests.org/
1
2
3
4
5
6
7
8
9
10>> import requests
>> r = requests.get('https://book.douban.com/subject/1084336/comments/')
get方法返回一个Response对象,这个对象里面包含Request请求信息 和服务器的Response响应信息 而Requests会自动解码 来自服务器的信息 假设某个网页的格式是json格式 那我们就可以利用Requests库中 内置的json解码器来解码 类似于这样的方式 :
re.json()
'
'
>> r.status_code
200 #代表一切正常
>> print(r.text)- 解码
- json格式
re.json()
- 二进制格式
re.content()
- re.text
自动推测文本编码,并进行解码
- re.encoding = ‘utf-8’
修改编码
- json格式
- 解码
- 遵循网站爬虫协议 robots.txt
BeautifulSoup
- 常用解析器
- LXML
- BeautifulSoup对象
- Tag : HTML,XML中的标签,大多数BeautifulSou对象都是Tag
- 属性
- name
- attrs
- 属性
- NavigableString
- BeautifulSoup
- Comment : NavigableString的子类
- Tag : HTML,XML中的标签,大多数BeautifulSou对象都是Tag
- 例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38from bs4 import BeautifulSoup
markup = '<p class="title"><b>The little Prince</b></p>'
soup = BeautifulSoup(markup, 'lxml')
print(soup.text)
The little Prince
type(soup.b)
Out[5]: bs4.element.Tag
soup.b
Out[6]: <b>The little Prince</b>
tag = soup.p
tag.name
Out[8]: 'p'
tag.attrs
Out[9]: {'class': ['title']}
#Tag属性的操作 和我们后面要讲的字典一样的 所以可以通过这样的方式来获取属性
tag['class']
Out[10]: ['title']
# NavigableString对象可以用string属性来表示
tag.string
Out[11]: 'The little Prince'
type(tag.string)
Out[12]: bs4.element.NavigableString # 后期很常用
soup.find_all('b') # 参数可以是标签或者属性名, 只需要找第一个可以用find方法
Out[13]: [<b>The little Prince</b>]
#find_all 方法返回一个列表
正则表达式
- 在线测试/调试工具
数据表示
序列
- 成员
- 字符串
- 元祖
- 列表
- 访问模式
- 元素从0开始通过下标偏移量访问
- 一次可访问一个或多个元素
操作
标准类型运算符
1
2
3值比较: < > <= >= == !=
布尔运算: not and or
对象身份比较: is is not序列类型运算符
获取,重复,连接,判断
- 内减函数运算符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15序列类型转换内建函数: list() str() tuple()
>>> list('Hello, World!')
['H', 'e', 'l', 'l', 'o', ',', ' ', 'W', 'o', 'r', 'l', 'd', '!']
>>> tuple("Hello, World!")
('H', 'e', 'l', 'l', 'o', ',', ' ', 'W', 'o', 'r', 'l', 'd', '!')
序列类型可用内建函数
enumerate()
reversed()
len()
sorted()
max()
sum()
min()
zip()
字符串
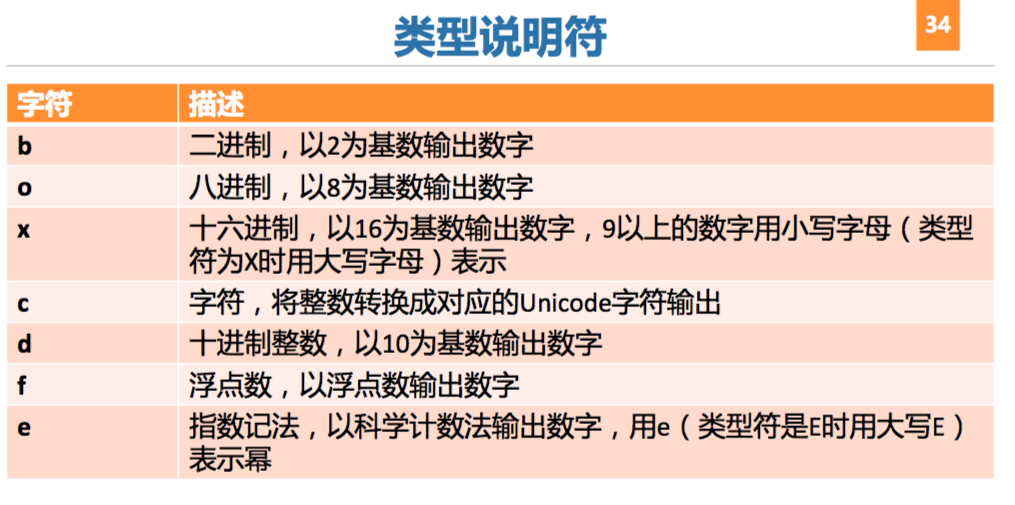
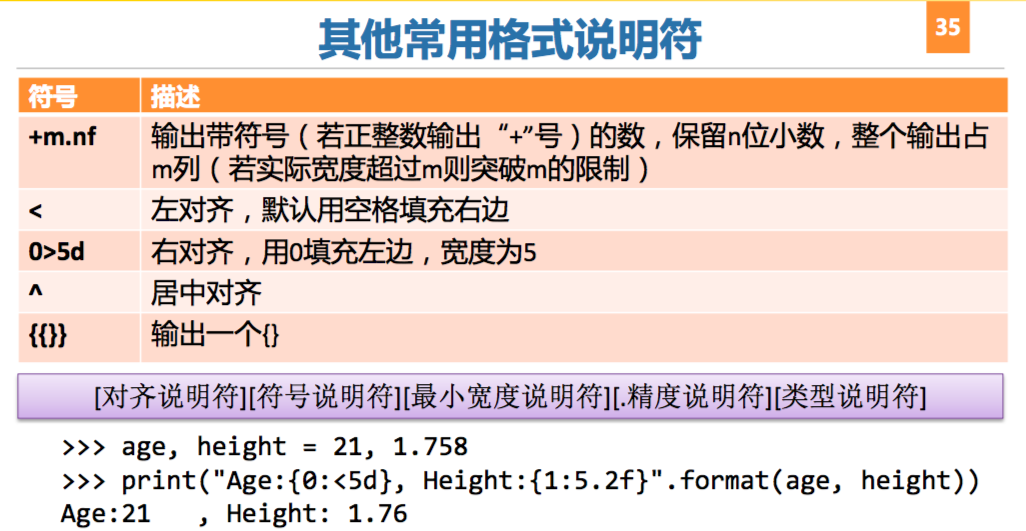
- 输出形式
- format_string % (arguments_to_convert)
- format_string.format(arguments_to_convert)
列表
- 可扩展的容器对象
- 包含不同类型对象
- 列表方法
- append()
- copy()
- count()
- extend()
- index()
- insert()
- pop()
- remove()
- reverse()
- sort()
- 列表解析
1
2
3
4
5
6
7
8>>> [x for x in range(10)]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> [x ** 2 for x in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> [x ** 2 for x in range(10) if x ** 2 < 50]
[0, 1, 4, 9, 16, 25, 36, 49]
>>> [(x+1, y+1) for x in range(2) for y in range(2)]
[(1, 1), (1, 2), (2, 1), (2,